Request Flow
The request flow for all requests is shown below for all operations. If the request originated from an HTTP request, there is a slightly different path flow in which the request itself is authenticated.
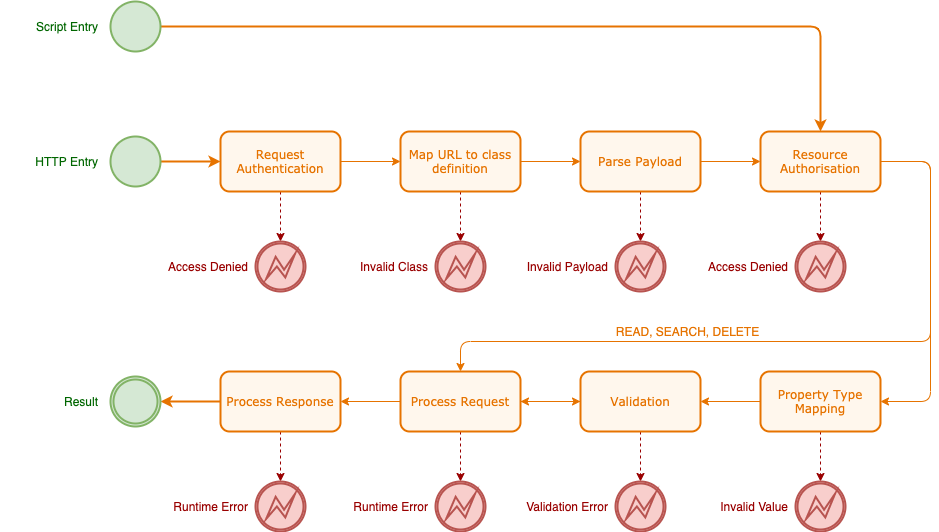
The request flow is broken into the following pieces.
- Request Authentication. Request authentication is the process by which an HTTP request is verified and trusted or rejected. The result of a successful request authentication is a subject. This is an object that is used throughout the request flow, in particular with resource authorisation.
- URL to Resource Class Mapping. This is the process whereby the URL is used to lookup the associated resoruce class definition. If the class cannot be found for the URL, then the request cannot progress.
- Parse Payload. Once the resource class has been identified, the payload is parsed. This travels with the request and is used within authorisation, validation and more.
- Resource Authorisation. Authorisation is the process through which resource objects are tested for access. Access may be derived from several sources such as the subject roles and permissions, request or resource attributes.
- Property Type Mapping. This is the process by which inbound property values are are checked against the property types in their respective resource classes. If the inbound value cannot be mapped to a type, then this mapping will fail and an error will be returned to the caller.
- Validation. Validators are used on classes and on class properties to test that the value of property or set of properties conforms to a specification as defined by those validators.
- Request Processing. By the time the request flow reaches this point, the request has been authenticated, authorised, validated and structurally tested for compatibility between the inbound payload and the target resource class. At this time, targeted scripts can be run, e.g. through class property rules, or through synchronous event handlers. If the request processing completes successfully, asynchronous events are queued up for delivery once the entire request completes.
- Response Processing. Response processing is only relevant when a payload is being returned to the caller. This is always true of READ and SEARCH operations but it can also be true of other operations if the caller has requested a payload via query string parameter. In these latter cases, the payload is the updated target resource object. Within the response processing, properties or potentially the entire object, can be determined to be inaccessible based on the resource permissions associated with the subject.
During a READ, SEARCH, DELETE and UPDATE operation, the current resource object is lazy loaded whenever the first attempt is made to read one of its properties. This could occur at any step within the request flow from Resource Authorisation through to the Request Processing.
The entire request flow operates within a single transaction, including all
events that are triggered through the flow. Custom events that are issued within
a request are also included in this transaction. It is possible to break out of
this primary transaction when saving objects via script by invoking the
api.resources.save(…)
function with flush=true. When this is done, the update occurs immediately
and is honoured even if there is a rollback of the primary transaction. External
operations, such as invoking an external APU, within a script inside the primary
transaction will not be rolled back
TODO - how to provide access rules for the SEARCH operation??