Modelling
Introduction
At its heart, Appirator is more about object modelling than API modelling. Appirator APIs are an important aspect of an Appirator application, but they are just one part of it. Without the object model, the API would not exist.
Consider an application on a mobile device. This application is a tool that allows users to manipulate business objects using rules and processes encoded into the model. It needs to communicate with an API in order to fetch and store its operational data properly with the service that runs it.
A common mistake made with API development is that the API and its associated microservices is a considered a core instrument for the business that is about as important as the business’ primary offering. Another common mistake made with API development is that it should be separate in design, and be protective, of backend modelling - the notion being that the backend model should not be exposed to the world because the world doesn’t need to know how we operate our business, so we’ll create an entirely separate model for the client. Both of these premises are not quite true.
Model Visibility
Two key considerations of businesses with a presence on the internet are:
- The client application or applications. These are the tools that the customers of the business use to interact with the business.
- The backend. This is where end user data is stored and processes occur with that data that help the customer in some way.
The common theme between these elements is the business object model. Appirator makes it possible to model entire backend applications and expose the only those parts of the model that the whole world should see. By exposing relevant parts of the model as an API, no work needs to be done at the server end in creating an API wrapper around the underlying server-side business model. Client applications consequently work with a model that exactly represents the public elements of the business model.
Take a model consisting of a number of public and protected resource classes, scripts, event handlers and more.
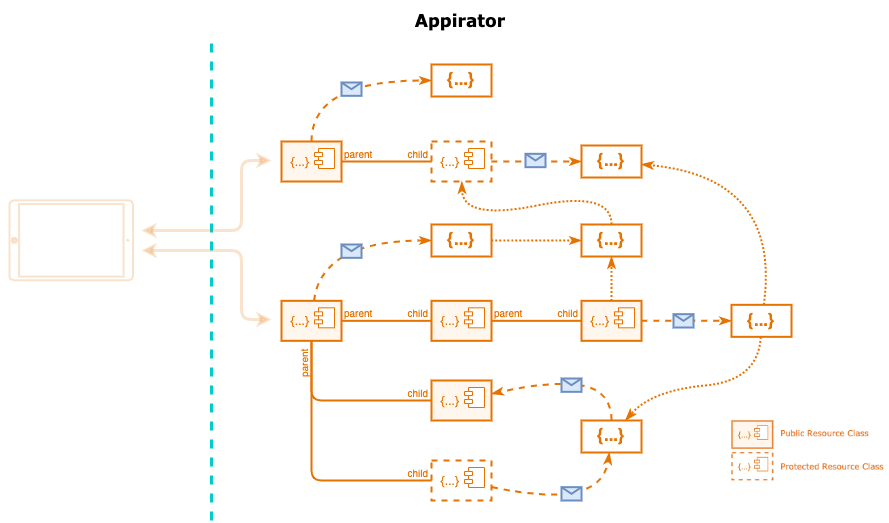
Only the public elements of this model are visible to the client and these appear as an API with several resource types. The client does not need to know what other parts of the model exist because it is only interacting with the public resources.
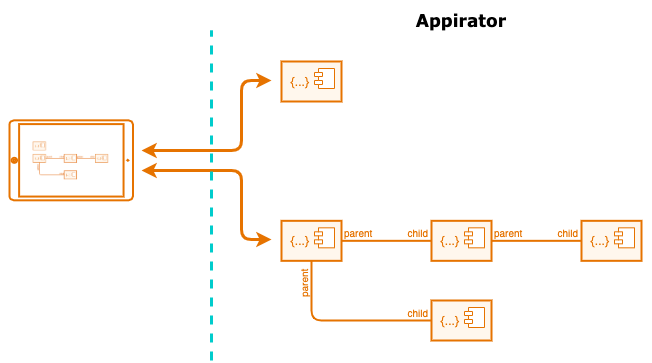
Resource Classes
Appirator models are made up from a number of model elements. These are described under Appirator Concepts. Arguably the most important of these elements is the resource class.
A class is a schema for an object instance and a resource class is a schema for a resource object instance. Resource objects can be stored in a store, can be passed through to custom stores and proxies, can undergo CRUDS operations and can be manipulated over API endpoints.
Non-resource classes can be created, but instances of these cannot be stored independently of a resource object. They can be nested inside a resource object to give the resource object depth and structure. Note that resource objects can be nested inside other resource objects as well, but these are stored independently of their enclosing object and a reference to the nested object is stored inside the enclosing object instead of a copy of the whole object being stored.
Creating a resource class is very easy. Take any non-resource class and give it
a modifier of RESOURCE and it is now a resource class and can be stored
and made an integral part of the model. If this class additionally needs to
be accessible over an API endpoint, then add another modifier PUBLIC.
This automatically results in an API endpoint created for it using the resource
class parent & child relationship to define its URL structure. If the resource
object has its persistence set to NONE, the object will not be storable,
but the CREATE operation will still be possible. Otherwise all CRUDS operations
will be allowed.
See Classes
for further information about class modifiers.
See Operations
for further information about CRUDS operations.
Creating The Model
Models should always be started by building the public resource class tree and these should always start with the primary top-most resource class. Once the top-most resource class has been identified, its child resource classes can be worked out. Much of the time the resulting tree identified through this process is all that’s needed to lay down a professional and quite complete model.
Example 1
The following model was created on request by a customer who provided these specifications:
- The model should support a multi-tenanted structure where the uppermost object is the tenant’s organisation.
- Members can be added to the organisation or invited in using high-level roles.
- Organisations run projects and its members can be assigned different roles within these projects. These projects have project facets.
- Some members might be permitted to work on a single project, others multiple projects, others just serve an organisation role and will not be assigned to projects.
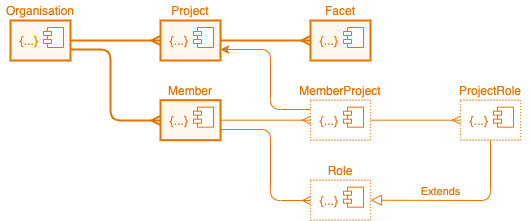
The resulting model can be seen above. This has the Organisation at the top with
children Project and Member. Projects have Facets and members have
child Roles relating to their organisational role and MemberProjects
that link to the project the member has been assigned to. This assignment comes
with one or more ProjectRoles. Role, ProjectRole and MemberProject
are not resource classes rather they are embedded within the Member class.
This model does not yet contain any event handling or scripting, yet it is
still a fully functional model which can already start being used. All of
the resource classes within the model are public and as yet there are no need
for protected resource classes.
If default API endpoints are used for this model, they will be:
/organisation/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Organisation)/organisation/<id>/project/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Project)/organisation/<id>/project/<id>/facet/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Project Facet)/organisation/<id>/member/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Member)
These default paths can be changed on the resource class declarations. Any of
these paths and/or their operations can be access restricted depending
on the subject that is trying to access them. Resource permissions can
be derived from the member Role, ProjectRole and MemberProject objects.
See Authentication & Authorisation
for more information.
Once the model is in place, the class properties can be filled in. These are the properties that can be set over their API endpoints or directly via the scripts within the model itself.
How else can this model be improved? It depends on the business requirements.
For example, there may be a requirement for the organisation to be activated
using an email verification. This is something that will need to happen through
an event handler script and an endpoint that is reserved for the verification. Upon
receipt of that request, the organisation status is updated. Such a process
can take advantage of the EphemberalToken class which is contained in the
Appirator Core module. This class is used to create short-lived tokens for the
purpose of verifying contact methods, but it can be used in any situtation that
requires a short-lived verification token.
Example 2
The customer described in Example 1 later made a request to extend their business model with the following specification:
- Organisations could manage one or more product catalogues.
- Only one product catalogue can be active at any given moment.
- Items within an organisation’s active product catalogue automatically become part of the ‘global’ catalogue which is a conglomeration of all items from the active catalogues from all organisations.
- Catalogue items can have artifacts, examples of which are: images, video, PDF specifications, etc.
- No indexing of catalogue item artifacts in order to save on storage costs.
The resulting model is shown below.
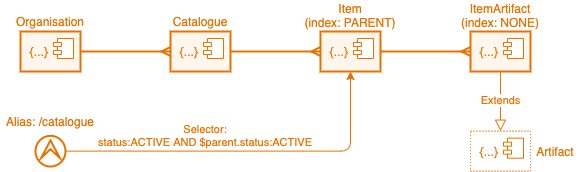
Before explaining this model, it is important to understand that by default
all persisted resource classes within a model, whether public or not, will
be indexed into Appirator’s backing Elasticsearch cluster where there is one
index used per resource class. It is possible to disable the indexing of a
resource class by setting its index to NONE.
Because these indexes are effectively isolated from one another, it is not possible to create join queries, however, there are two exceptions to this:
- By default, the following will be indexed with the resource object being indexed:
- The parent object id, which is indexed as
$parent.$id. - The parent object’s class id, which is indexed as
$parent.$class.$id. - The class id of the object being indexed, which is indexed as
$class.$id. The grandparent details of an object is not indexed, so it is not normally possible to reference this in a query.
- The parent object id, which is indexed as
- By setting the
indexof a class to PARENT, the object will be indexed in the same index shard as each of the parent objects and there will be a parent/child relation set up between them in the index. This allows the properties of the parent to be referenced during a query of the child. In the case above, this can be seen with$parent.status:ACTIVE. This is similar to a relational DB join, but is restricted to referencing the parent object details only. Note that if there is a chain of objects being stored in a top-level parent’s index (e.g. bothCatalogueandItemare stored in the index ofOrganisation), then each of these can be queried when making a query of the deeper objects, so technically it would be possible to make a query like$parent.$parent.status:ACTIVEwhen querying theItem, although this would be a fairly slow query because there are two joins involved.
The reason why this has been done in the model above is to permit the global catalogue
which is accessible under the URL alias /catalogue to reference the
Items from the ACTIVE Catalogues from all Organisations and not their
INACTIVE Catalogues.
The global catalogue is a list of catalogue items that are derived from the
query status:ACTIVE AND $parent.status:ACTIVE which states: give me all
active items from all active catalogues regardless of their organisation. This
property is restricted to READ and SEARCH operations only through
resource permissions which are not shown here. This
results in the following endpoints, which can be further restricted through
resource permissions as needed:
/organisation/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Organisation)/organisation/<id>/catalogue/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Catalogue)/organisation/<id>/catalogue/<id>/item/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Catalogue Item)/organisation/<id>/catalogue/<id>/item/<id>/artifact/[<id>](CREATE, READ, UPDATE, DELETE Item Artifact)/catalogue/[<id>|?term=...](READ, SEARCH Global Catalogue Items)/catalogue/<id>/artifact/[<id>|?term=...](READ, SEARCH Global Catalogue Item Artifacts)
A final note on this example: The class Artifact is a class that is built
into the Appirator core module and it comes complete with all of the machinery
needed to create, upload and update the associated real artifact. By extending this
class, ItemArtifact inherits this behaviour. Instances of these classes
are not the uploaded objects, but are pointers to them. Once an artifact is created,
a URL is reserved for the artifact. The client must PUT the object to that URL.
Once the PUT (i.e. the upload) is complete, Appirator will receive a notification that the
upload is complete and mark the associated ItemArtifact object as COMPLETE.
See Binary Artifacts for more information.
Third Party Modules
Appirator applications are modular. Modules contain reusable model segments together with their associated events, handlers, common library code, business logic and resource class migration logic. Modules can be imported into any Appirator application from a few sources:
- From various sites around the internet who provide Appirator modules.
- From Appirator itself using Appirator’s own modules.
- From the Appirator marketplace or any other compatible marketplace.
Appirator-supplied modules are free to import into any application, but others may not be. Some will have license costs. Irrespective of whether there is a one off or periodic licensing cost for a module, there will always be usage charges associated with any resource object storage, file storage, bandwidth and CPU consumption.
It is important to note that third party modules are likely to include several model elements that are not used in the final application. Those model segments that are not used do not incur a usage change because they consume no platform resources.
Example 3
A blog developer needs to create a blogging backend application with relevant API endpoints including sign up, login, the ability for bloggers to create and publish blog articles, the ability for other users to review and comment on the blogs, the ability for blog owners to invite other users of the platform to be bloggers within their blogs.
The resulting model is shown below.
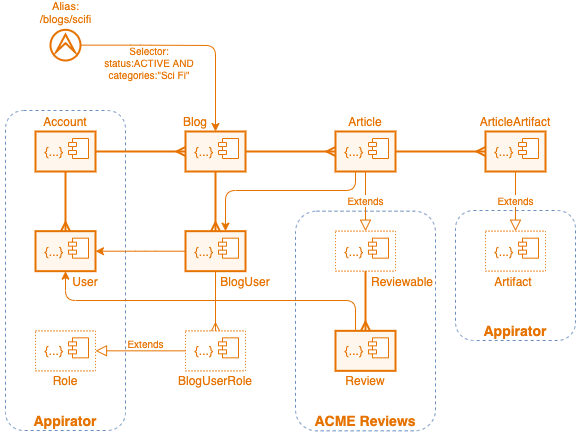
This model might seem complex, but it’s actually very similar to the model defined in example 1 with parts of example 2 thrown in for good measure.
The important part of what is being shown here is the reuse of model components
from other modules. In particular the use of the Account, User and Role classes
from the Appirator accounts module, Artifact from the Appirator core module
and Reviewable and Review from the module Reviews from the fictitious company ACME.
In this latter case, the module may have been found somewhere on the internet
or it may have been found in the Appirator marketplace. In this example, the
abstract Reviewable class contains properties:
ratingwhich is an aggregate of all the ratings from the individual reviews; andreviewswhich is the list of individualReviewresource objects.
By extending this class, Article inherites these properties and all of the
business logic that drives them from the Reviewable class.
The Review resource class has properties:
ratingwhich is the individual rating of the review.commentwhich is a textual comment by the reviewing user.userwhich is a link back to the reviewingUser.
This class and the Reviewable class carry with them business logic to manage
and aggregate reviews and ratings for the blog articles. As reviews are added
the asynchronous CREATE event for the Review class is captured and this event
is forwarded to its parent, the Article class, where it is used to send a
notification to each of the contributors of the blog article.
The API endpoint paths for the model above are:
/account/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Organisation/Indivudal Account)/account/<id>/user/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Account User)/account/<id>/blog/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Account Blog)/account/<id>/blog/<id>/blog-user/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Blog User)/account/<id>/blog/<id>/article/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Blog Article)/account/<id>/blog/<id>/article/<id>/artifact/[<id>](CREATE, READ, UPDATE, DELETE Article Artifact)/account/<id>/blog/<id>/article/<id>/user/[<id>](READ Article Contributor)/account/<id>/blog/<id>/article/<id>/reviews/[<id>|?term=...](READ, SEARCH Article Review)/blogs/scifi/[<blog-id>|?term=...](READ, SEARCH Blog)/blogs/scifi/<blog-id>/article/[<id>|?term=...](READ, SEARCH Blog Article)/blogs/scifi/<blog-id>/article/<id>/artifact/[<id>](READ Article Artifact)/blogs/scifi/<blog-id>/article/<id>/user/[<id>](READ Article Contributor)/blogs/scifi/<blog-id>/article/<id>/reviews/[<id>|?term=...](CREATE, READ, UPDATE, DELETE, SEARCH Article Review)
The example presented above is a simple use case where a very small functional model segment was used from a third party module. The reality is though, that there are likely to be a large number of third party modules available containing both large and small segments of models. Some modules will contain entire ecosystems, for example, entire billing or CRM engines, while others will contain segments like that above or small chat engines, PDF processing, etc. Regardless of the size of model segment being used, business can potentially save vast sums in reusing these components rather than reinventing them.