What is Appirator?
History of Server-Side Development
Before delving into the ins and outs of what Appirator is, it is important to understand the history of server-side computing.
Back in the 90s, businesses either had to create their own data centres or rent space in them using their own purchased or rented physical servers. These machines were very expensive to purchase and required specialist operations staff to set them up and maintain them. The environments that these machines were configured into were static and consequently needed to accommodate traffic and storage volumes well in excess of the average daily peak.
Then came virtual servers. These are physical servers that have been divvied up into several virtual machines. The benefit of these are that they’re fairly quick to spin up and they can be reallocated when they’re no longer needed within a specific environment. Their downside is that they still require operations staff to manage and even though they’re virtualised, environments using these servers are still quite static by design.
One of the big problems we saw during the days of physical and virtual private servers was the disconnect between development and operations staff. It wasn’t uncommon for businesses to see conflict between these teams. Operations staff were highly resistant to changing their environments, and this led to developers feeling like they were being blocked in their work.
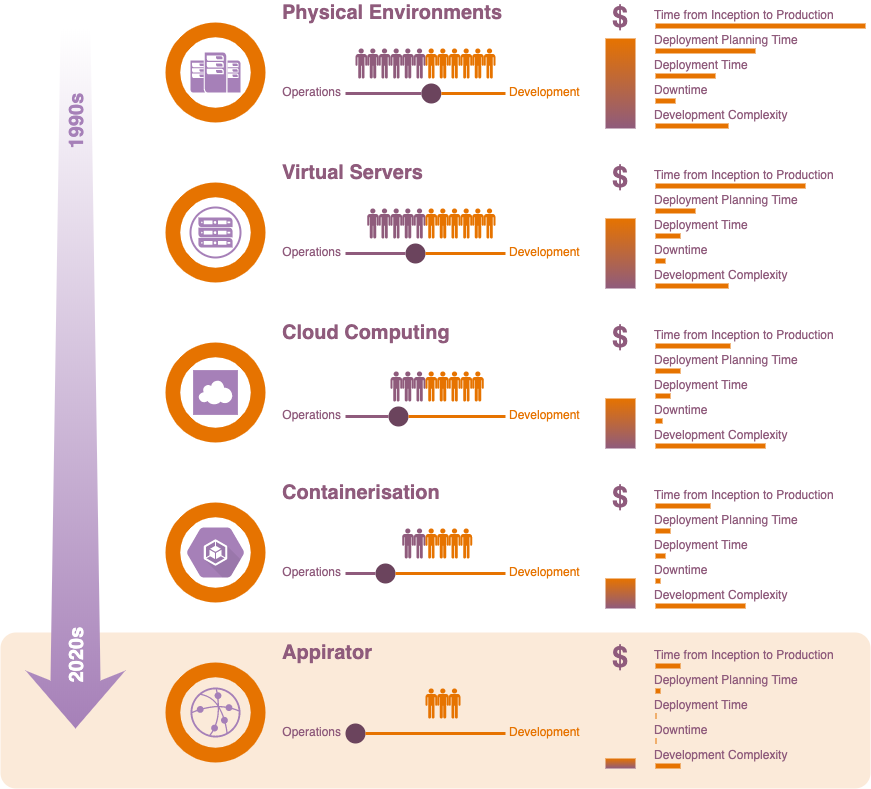
In the late 2000s, along came AWS and they hit the tech industry with an eye opening ton of bricks. AWS came with all of the stuff that developers needed to set up their own infrastructures, all without the obstruction that operations teams were previously bringing them. The caveat was that they had to become operations teams themselves and with that, DevOps was born. While DevOps and cloud computing gave developers the opportunity to create their own environments for their applications, it resulted in that same complexity being added to their workload. As a result, developers had to become skilled in scripted infrastructures, CI/CD, pipelines, monitoring and more, which, as it turns out, is a lot of work.
The next piece in this computational puzzle came with the advent of containers. Containers are thin layers sitting on a host operating system that emulate the operating system in isolation from all other sibling containers and from the host operating system itself. Because they’re just a thin layer, they’re very fast to spin up - often only a few hundred milliseconds. They can run any software that the host could run. This makes them perfect for applications that need to be scaled and redeployed quickly. But containers come with their own headaches, particularly when used to support microservices environments, which became the flavour of the month with developers in the late 2010s.
So what’s the problem?
- An operating environment needs to be created for each application to run on.
- Application environments need to be capable of scaling or they need to be built pre-scaled.
- A large portion of the development being performed is not satisfying a business function.
- And these items are costly because:
- They require DevOps development time.
- They result in complexity which puts the application at a greater risk of faults.
- They can result in complex BAU maintenance.
- They normally require dedicated cloud infrastructure which, more often than not, is used inefficiently.
Despite all the improvements that have been made in easing the path for developers to get their server-side applications out onto the internet, there still exists the infrastructure and operational burden. In addition to this, while the cost of bring applications online has decreased over the years, because the operations element continues to exist, IT budgets still require a significant allotment when it comes to operations and infrastructure development.
This is where Appirator comes in.
Appirator
Appirator is many things, but in particular …
1) Appirator is a computational continuum.
2) Appirator is a framework with which to build applications within this continuum.
Appirator, or any similar framework, is an inevitable next step in the evolution of server-side applications. Not only does it remove knowledge of the operating environment in which applications run, and this incidentally means that there are no DevOps or infrastructure costs, but these applications run throughout the entire continuum, not just on specific nodes as is the case with all other models to date. That means that if the Appirator continuum consisted of 1 million compute nodes, a given application could run on 1 or on all of the nodes within the continuum at some point in its life.
This works because almost all modern applications are event driven. Processes within applications are either triggered through external requests, e.g. HTTP requests, or through internal events which may be scheduled or they may be reactionary. In any application, when an event of this nature occurs, cogs run, stuff happens, and then the application settles in, waiting for the next thing to do. Appirator works in the same way except that the application itself doesn’t exist within the continuum unless it is active, and when it is active, only the part of the application that needs to be present is present. All other parts of the application remain quiesced.
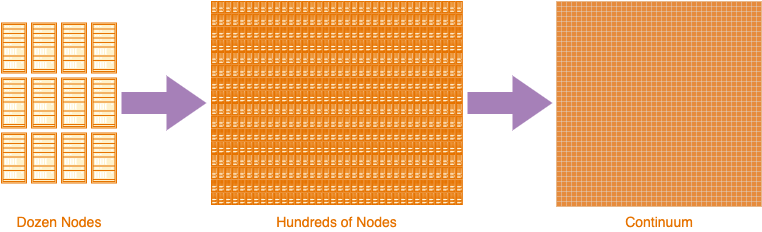
The Appirator framework is a whole solution, meaning that it is possible to create an entire application that runs within the continuum and developers don’t need to make calls outside the continuum unless there is either an external dependency required or if they need to run something natively, e.g. if a process needs to run something that requires specific operating system features. This whole solution includes object storage, messaging, event management and much more.
The Appirator continuum is a multi-layered ecosystem that is, among other things, self persisting. Once objects are created, either through HTTP requests or through scripts that run within the continuum, the objects are persisted automatically, ready and waiting for the next request. Of course, this behaviour can be changed, but it’s there by default.
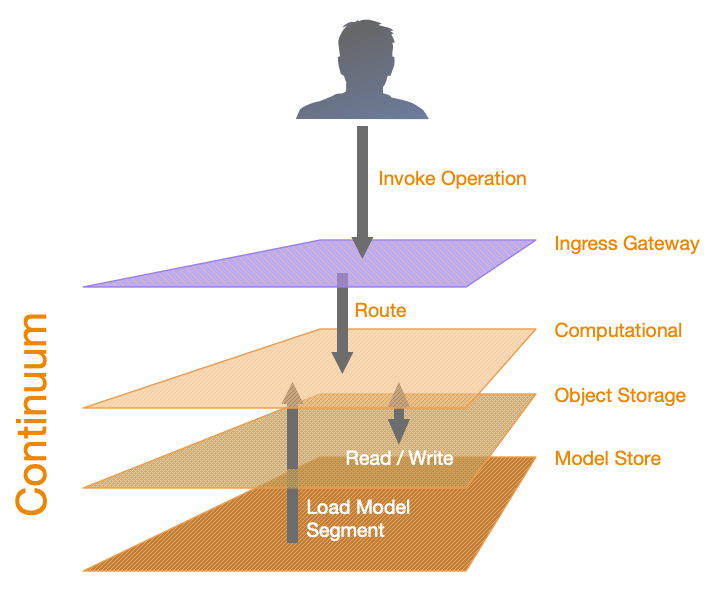
In a simple request to a model endpoint within an application, the request enters the Appirator ingress gateway, which intelligently routes the request to the most efficient node within the continuum. The node pulls the model segment related to the request into memory, if it is not already cached, and runs it. Appirator will also read and persist objects as needed. If a simple request like this is doing nothing more than reading and persisting object data, validating access and object properties, and sending events, no coding is necessary.
Containerisation vs. Appirator Development
There’s a big difference in the way that containerised development differs from Appirator development, mainly based on two core differences:
- Appirator applications have no requirement for infrastructure and thus there is no need for DevOps or DevOps teams.
- Appirator objects are self persisting and self indexing, so there is no need for data stores.
The two main differences between traditional server-side application development results in a significant difference in the things that organisations and their development teams need to consider when building applications. The table below highlights these differences on a typical project that could either use containerised development or development under Appirator.
| Considerations | Under Containerisation | Under Appirator |
|---|---|---|
| Project Planning | ✓ | ✓ |
| Design & Documentation | ✓ | ✓ |
| Collaboration & Task Management (e.g. JIRA, Slack, etc) | ✓ | ✓ |
| Cloud Account Management (Developer permissions, etc) | ✓ | ✓ |
| CI/CD Platform & Maintenance | ✓ | Built-in |
| Cloud Infrastructure & Servers | ✓ | N/A |
| Container Management | ✓ | N/A |
| Container Security & Routing | ✓ | N/A |
| Cloud Platform Integrations (Queues, File Storage, etc) | ✓ | N/A |
| DevOps Scripting | ✓ | N/A |
| Application/API Platform (Node, Python, etc) | ✓ | N/A |
| Application/API Development | ✓ | ✓ |
| Git Management | ✓ | ✓ |
| Database Management | ✓ | N/A |
| Database Schema Design & Creation | ✓ | N/A |
| Database Schema Updates | ✓ | N/A |
| PKI & Certificate Management | ✓ | Optional |
| Credential Management & Hardware Encryption | ✓ | Built-in |
| PCIDSS Planning & Compliance | ✓ | Built-in |
| Server Monitoring | ✓ | N/A |
| Analytics | ✓ | Built-in |
| Log Collection (e.g. to Splunk) | ✓ | Optional |
Key:
- ✓ : The consideration is normally required and the organisation will consequently need to provide time and funds for people to deal with it.
- Built-in : The consideration is built into the framework and can be accessed when required with no additional development.
- N/A : The consideration is not relevant.
- Optional : The consideration is built in, but there is a provision to use an external process if the provided service is insufficient.
In the case of PKI & Certificate Management, developers can use external CDNs which host private TLS certificates. It is also possible to use private TLS certificates with Appirator’s default CDN.
In the case of PCIDSS Planning & Compliance, while the Appirator continuum is PCIDSS compliant from a platform perspective, it is still the responsibility of the developer to ensure that their object model is also compliant. Fortunately developers can reuse existing modules for this, such as the Appirator Payments module, which is PCIDSS compliant and can isolate developers from card interactions.
Human Resource differences
As can be seen above, there are a number of consideration differences between developing using containers vs. development using Appirator. These difference have consequences in the types of people that need to be deployed into Appirator projects.
Example
An organisation undertakes a project to build a server-side application with an expected duration of 6 months. After the completion of the project, there will be ongoing level 3 technical support as well as intermittent fixes and functional changes that need to be tested before deployment to production.
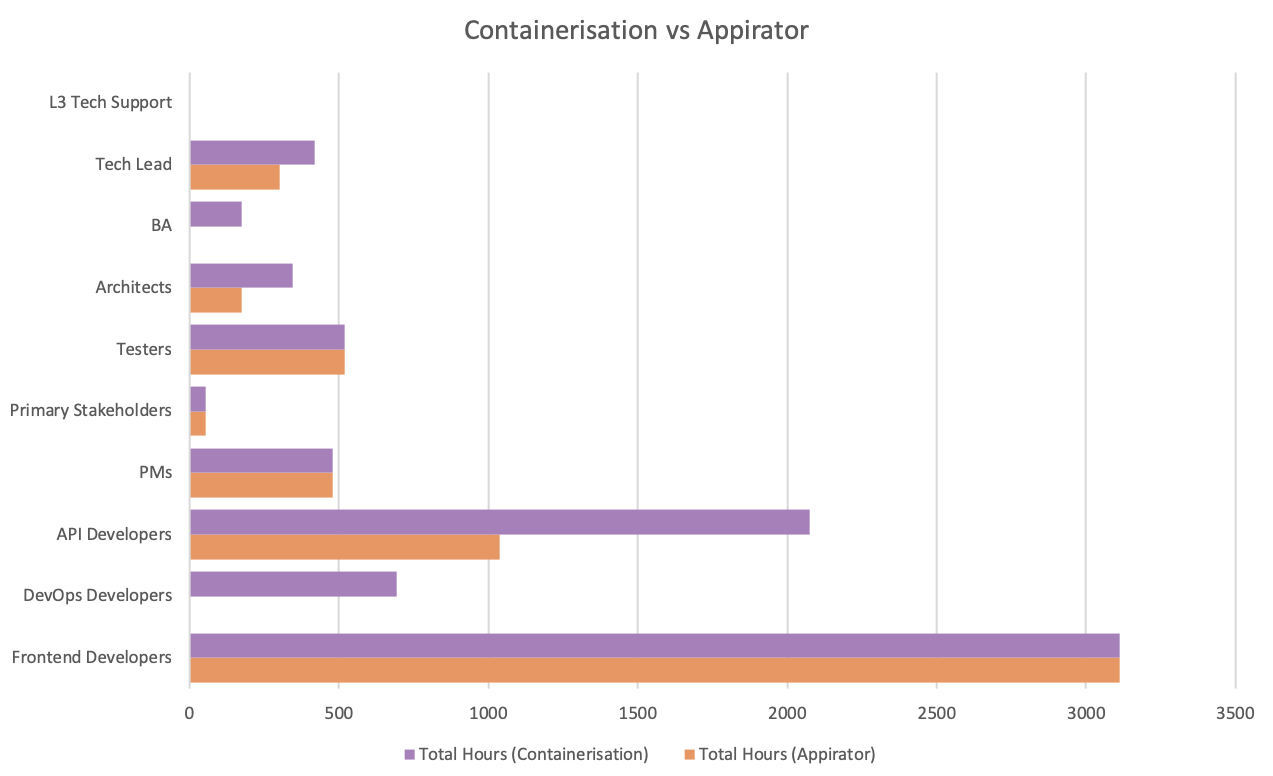
The man hours required during the project development can be seen in the diagram below.
Upon completion of the project, the platform enters BAU and the monthly man hours can be seen below.
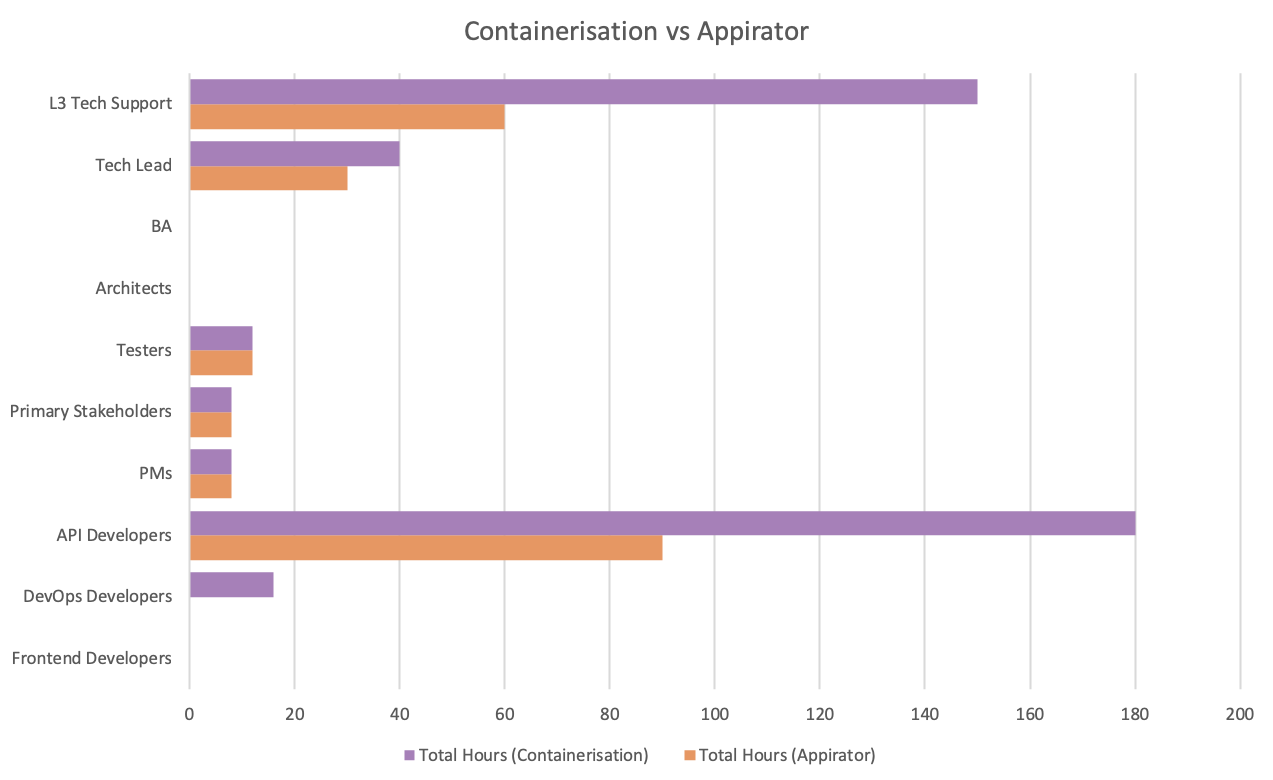
This example shows that:
- During project development, there is a 28% reduction in man hours if using Appirator instead of containers. It is important to note that this is a conservative estimate. For more complex projects, the savings could be significantly higher because there is more likely to be a greater reuse of shared modules. It is also important to note, that most server-side development doesn’t ever settle into pure BAU but rather it typically falls into cycles of smaller projects and BAU operations typically run along side these smaller projects, so there ends up being perpetual savings when using Appirator.
- During BAU, there is around a 50% reduction in man hours if using Appirator instead of containers.
Where do these differences come from?
From the charts above, it is clear that there are savings with the following teams:
- DevOps developers & L3 tech support. Appirator requires no infrastructure to be spun up or managed. Consequently there’s no need for a DevOps team and there are no servers for L3 support teams to monitor and manage. As a result the role of the L3 teams are reduced to functional technical support of the application itself.
- Tech leads & application/API developers. With the reduction in complexity of the environments as well as the fact that server-side developers can draw on the resources of available shared modules, there is a corresponding reduction man hours required by these teams.
- Architecture and BA work is reduced during project development because the only thing that needs to be considered from a design point of view is business modelling and not modelling of the infrastructure.
Appirator vs. Cloud Functions vs. Microservices
There is a very big difference between Appirator applications, cloud functions and microservices. These are elaborated in detail in the following table.
| Appirator | Cloud Functions | Microservices | |
|---|---|---|---|
| Cold start issues | Appirator is always hot and thus doesn't suffer from cold start issues. However, Appirator application models are quiesced while not active and it can take between 1 and 100ms to load the appropriate model details for a request if it has not been loaded recently. | Cold start issues are a well known problem with cloud functions. These can be minimised by using languages that are known to start faster, such as Node or Python instead of Java. | Microservices are not indented to be spun up per request, so cold start issues are not a problem. |
| Scalability | The Appirator continuum is an infinitely scaled mesh of compute nodes that grows and shrinks as it needs to accommodate the entire spectrum of processes that are running at any given time. Consequently applications are always in an appropriately scaled state. | Cloud functions are spun up as needed with restrictions applied in their configuration by the developer. So they scale with no additional development work required. | Scaling microservices is something that has to be configured into their respective containers and into their containing environments. This is not necessarily complex but it does mean that containers are left in a wasteful idle state much of the time. |
| Invocation leftover files | Appirator invocations are always isolated from one another. Each invocation receives its own file system, which has ephemeral and permanent parts to it. At the end of the invocation, all files within the ephemeral part are automatically deleted, while those in the permanent part remain behind and are available across invocations. | Cloud functions are typically invoked as warm containers where possible, where the container will remain alive if there is a high enough invocation frequency. The file systems used in these containers are static for the life of the container and as a result, files can get left behind between invocations if they are not expressly deleted by the code being run in the function. The same is true of objects in memory and operating system processes not being explicitly destroyed at the end of the invocation. This can lead to unexpected behaviour as well as security concerns. | Microservices are designed to be static by their nature so files and processes created during invocations need to be managed by the business logic within the microservice. |
| Work not related to a primary business function | Appirator requires no infrastructure to be configured and is thus entirely DevOps free. For this reason developers can concentrate on developing business functions and not on infrastructure coding. | If the cloud functions are configured in an automated way, DevOps scripting is required to keep them up to date. If not, then updating these functions is a manual process, which can be very error prone and tedious process when there are many cloud functions being managed. | Managing microservices is an infrastructure burden and thus requires DevOps work to keep them in check. |
| Ease of development | Appirator project development is essentially pure business logic development and is object model based. This will be very familiar to developers who are used to object orient design and development. A single application is a collection of modules, classes and their associated rules, methods, validations, event handlers and migrations. | Each cloud function needs to be developed as a separate, very granular, mini project. It is possible to use a common framework to support situations where there are many cloud functions that share a common pattern, but this is likely to be a custom, in-house framework if it's done. | Microservices development is somewhat similar to cloud functions development in that it is normally done under quite granular mini projects. Connecting related microservices that are run under independent containers can be quite tricky and requires specialised routing logic within the container manager. |
| Ease of deployment | Appirator has a built-in deployment pipeline mechanism, eliminating the need for external CI/CD systems. | Deployment is either though DevOps scripts initiated through a CI/CD pipeline or manual. | CI/CD pipelines are used to deploy the microservices into their respective containers normally, although it is possible to do this manually through commandline tools. |
| Locating the whole application | Appirator applications are natively whole applications. It is possible to silo parts of these applications in a similar way to microservices. These siloed segments can take up different parts of a domain scope and they can be linked together in a way that makes the larger application feel like a single application. | Cloud functions only represent a small fraction of the entire application. The rest of the application could be spread across many other areas including among other serverless scopes, part of microservices and in application platforms such as Node or Python. | Microservices are, by definition, pieces of a whole application. They are typically run under separate containers, which makes it tricky to get them talking to one another. Solutions such as service meshes have been developed to solve this problem. The very existence of service meshes is an indicator that microservices are being used in a way that is unnecessarily complex. |
| Object storage | Appirator persists resource objects by default in its own internal store. Resource objects can also be stored or proxied to external stores. Persistence can be disabled on a per-class basis. Resource objects that are stored in Appirator's internal store are automatically added to its Elasticsearch index unless this is disabled. | Cloud functions have no built-in storage and depend on datastores outside the function if it is needed. | Like cloud functions, microservices have no built-in storage and this needs to be set up outside the microservice when it is needed. Microservice design normally dictates that each microservice has an independent store from every other microservice. This makes datastore management complex and extremely cumbersome. |
| Data schema updates | Appirator has a built in mechanism to upgrade or downgrade objects that are already persisted, including in external stores. When an application or module is updated, any updates that are needed in an object as a result of changes to their respective classes happen as the object is being read from storage. | Cloud functions do not have built-in storage, so any updates to their external database schemas need to be done independently of the cloud function and its surrounding application. | Like cloud functions, microservices have no built-in storage and updates to their external database schemas need to be done independently of the microservice and its surrounding application. |
| API Gateway & Routing | Appirator has its own gateway functionality with smart routing that directs requests to the best node within the Appirator continuum. Nothing needs to be configured for this to work as it happens automatically. | Cloud functions have no internal routing and depend on an ingress gateway if they are the endpoints of an API request. The API gateway needs to be configured independently of the cloud function. | Container management systems such as Kubernetes have their own internal routing mechansim and they can optionally use platforms such as Nginx as a gateway and for routing. It is normally recommended, however, that theses environments be protected with an ingress gateway regardless. In all cases, the gateway and the routing is configured independently of the microservices. |
Appirator Framework Features
Framework Language Features
Appirator models are built using classes, modules, validators and event handlers using YAML or JSON files that are compiled into an assembly. The YAML or JSON contains language constructs similar to a programming language and these constructs are used to define the model for a given application or module.
The following language constructs are available in the framework.
- Class Trees, Inheritance & Polymorphism
- Class & Property Validation
- Methods
- Modules
- Object Migration
- Class Augmentation
- Persistence
- Lookups
- Class & Property-Level Access Control
- Search
- Events
- Operations
- Stores & Proxies
- RESTful API Endpoints
Framework Internal Functional Features
In a similar way that Node and Python have internal modules, Appirator has a set of internal libraries that are part of the framework. These allow developers to create whole applications without the need to make external calls. These features include those listed below but this is not an exhaustive list.
- Scheduling
- Ephemeral & Persistent File Management
- File Upload & Storage
- Polyglottal Scripting
- HTTP, TCP & RESTful API Ingress
- HTTP & TCP Outbound Communications
- Generated & Custom Domains
- Security & Crypto
- Authentication & Authorisation
- Logging & Audit
- Analytics
- Messaging
In addition, while not part of the framework specification, Appirator permits direct Git Integration so that pushes to nominated Git branches automatically result in a build and optionally a publish of the application.
Application Transportability
No organisation wants to lock themselves into a particular provider. For this reason, the Appirator framework specification is an open specification that other providers can implement as they see fit. If other providers implement the framework specification correctly, any application written to run within the Appirator continuum will also run within the other provider’s environment. If this is done, however, any data stored within the Appirator continuum will need to be exported and imported into the other provider.